I recently used an AI humanizer to try and pass Originality AI’s detection for some long-form content, but I’m getting mixed results and contradictory scores. Sometimes it flags my writing as heavily AI-generated even after humanizing, other times it passes with no issues. Can anyone explain how reliable these tools are, what settings or methods actually work, and whether it’s safe to rely on an Originality AI humanizer for client work or publishing online?
Originality AI Humanizer Review, from someone who tried to force it to work
Originality AI Humanizer Review
I went into this one with higher expectations than usual. Originality is known for detection, so I thought their humanizer would at least do the basics. It did not, for me.
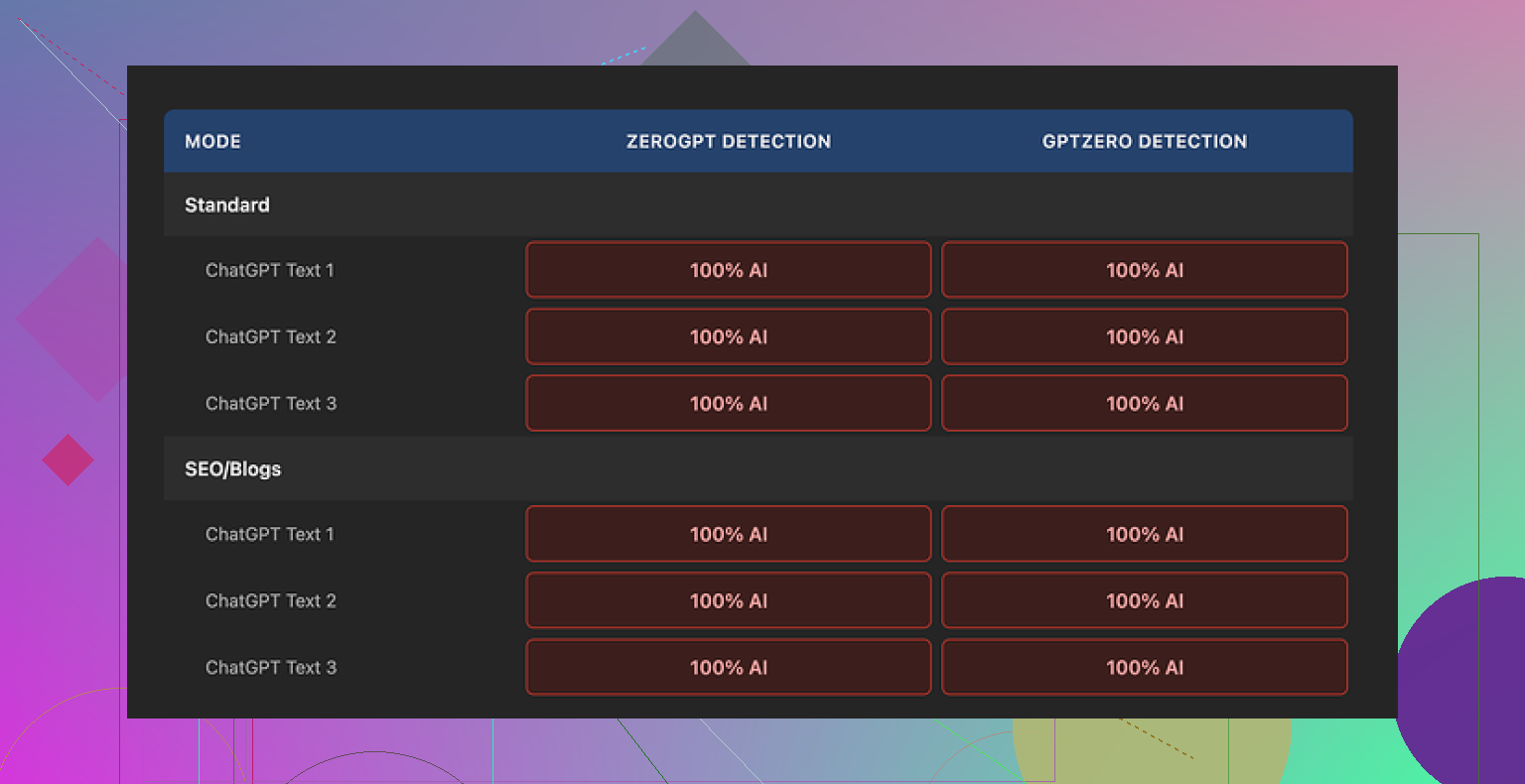
I pushed multiple samples through the Originality AI Humanizer, then ran every result through GPTZero and ZeroGPT. Here is the short version of what happened:
Every single output got flagged as 100% AI on both detectors. No variation, no borderline scores, nothing. I tried:
• Their Standard mode
• Their SEO/Blogs mode
Same result. No improvement on any of the runs.
What the tool actually does to your text
The reason became obvious once I compared input and output line by line.
The humanizer barely touches the content. It keeps:
• The same sentence patterns
• The same structure
• The same overused AI filler words
• The same em dashes and rhythm you see in stock ChatGPT text
If you paste a robotic paragraph into it, you get the same paragraph back with a couple of synonyms swapped. That is not enough to change how detectors read it.
Because the edits are so light, you end up in a weird spot. You try to judge the quality of the humanizer, but you mostly end up judging the original ChatGPT output. The tool does not add a voice, does not change pacing, and does not break patterns that detectors look for.
So, from a bypass point of view, it did nothing useful in my tests.
What is nice about it, to be fair
To avoid sounding like I am trashing it for sport, a few things are decent.
• It is free to use, no login needed
• Word limit is 300 words per run
• There is an output length slider, so you can tell it to shorten or expand a bit
• The privacy policy looks carefully written, and they include a retroactive opt-out for AI training, which I do not see everywhere
The 300 word cap slowed me down, but I worked around it by opening new incognito windows and pasting fresh chunks in each time. A bit annoying, but it works if you are stubborn.
The bigger issue is direction, not features
After a few tests, it felt less like a serious humanizer and more like a funnel.
You land on the free humanizer.
You see poor bypass results.
Then you see their paid detection product everywhere.
It looks like the real business here is the detection side, and the humanizer is there to bring search traffic into that system.
If your goal is to clean up wording for human readers, it can sort of help, since it behaves like a light paraphraser. If your goal is to get past AI detection tools, my experience was that it did nothing.
Alternative that worked better for me
After trying a bunch of these tools back to back, the only one that consistently gave me better quality and better scores on detectors was Clever AI Humanizer. It is here:
In my runs, it handled structure and word choice more aggressively while keeping meaning intact, and it stayed free.
If you only care about bypass, I would skip Originality’s humanizer for now and use something that changes the text in a more meaningful way.
3 Likes
You are seeing mixed and contradictory scores because detectors are noisy and your text is probably sitting in a grey zone.
A few points from my own testing that are a bit different from what @mikeappsreviewer shared.
-
Originality “humanizer” behavior
• It behaves like a light paraphraser for me too, but I did get some small shifts in scores when I changed:- Sentence length variation.
- Paragraph breaks.
- Use of lists vs plain paragraphs.
• If you paste 1,000+ words, chop it into genuine sections by topic, not random 300 word chunks. Detectors seem to look at local patterns. If each section has a clear subtopic and slightly different style, scores move more.
• If your base text is pure ChatGPT stock style, tiny tweaks will not push it past thresholds. The “voice” is still uniform.
-
Why scores look random
• Detectors use probabilistic models.
• Change 2 or 3 high probability tokens in a sentence, the score can swing a lot.
• They also update models in the background. The same text on different days can get different scores.
• Cross tool comparison is worse. GPTZero, ZeroGPT, Originality, Winston etc all use different signals. You will never get full agreement. -
Things that moved Originality scores the most for me
These are practical edits you do yourself, not with a humanizer.
• Insert short personal details that an LLM would not guess.
Example: specific dates, tools, versions, your own wrong assumptions, quick asides like “I wasted two days on this part”.
• Keep some typos and imperfect sentences, similar to how you write in chat or email.
• Change structure.- Merge some short sentences.
- Break some long ones.
- Add questions and answers.
• Add light domain mistakes then correct them.
Example in a dev post: “I first tried to fix this in the nginx conf, which made no sense, then moved it to the app layer.”
These are the sort of things detectors treat as human-like variance.
-
About “humanizers” as a strategy
I slightly disagree with the idea that they are useless across the board. They help if you already have a human base and you use them as a secondary tool. If your input is pure AI, they mostly shuffle words and you get the same flags.
If you want something more aggressive, Clever Ai Humanizer did a better job of changing rhythm and syntax in my tests. It still needs a human pass after. -
If your goal is safer long form
• Start from your own outline.
• Use AI to expand specific points, not whole chapters.
• Rewrite each chunk in your own words.
• Add your own examples, mistakes, and opinions.
• Run the final through Originality once, not ten times. Obsessing over a number will waste your time. -
When to stop tweaking
If you have:
• Unique structure.
• Personal details.
• Natural errors and corrections.
and Originality still says something like 40–60 percent AI, I would stop. At that point you get into false positive territory. Detectors are not an authority on your honesty, they are pattern classifiers with error rates.
If you keep using tools, use Originality’s humanizer only as a light helper for wording and flow. For serious “pass the detector” work, combine manual editing, Clever Ai Humanizer for heavier rewrites, plus authentic personal content.
You’re not crazy, the mixed / contradicting scores happen a lot, even when you do “everything right.”
I mostly agree with what @mikeappsreviewer and @sonhadordobosque said, but I’d push back on one thing: I don’t think the core issue is just that Originality’s humanizer is “too light.” The bigger problem is that you’re trying to solve a probabilistic classifier with a binary mindset: “pass” vs “fail.”
A few things from my own testing:
-
Detectors are not stable tools
- Same text, different run, different score.
- Same text, same tool, different model version in the background, score moves again.
- You’re seeing “contradiction” because the system itself is noisy, not because you messed up.
-
Long form is a special kind of pain
Originality seems harsher on long, consistent pieces. If your 2,000+ words all “feel” like one continuous AI narrative, it only needs a portion of that to trigger.
Chopping it into 300 word pieces and running each through the humanizer usually just creates 7–8 slightly paraphrased AI-style chunks. When you stitch them back together, the overall pattern is still obvious. -
Why your “human-sounding” edits still get flagged
Stuff I see a lot:- Replacing words with synonyms.
- Inserting generic opinions like “In my experience, this is very important.”
- Adding a token typo or two.
Detectors are not looking for obvious mistakes or buzzwords only. They look at token distribution and how predictable the sequence is. You can have “human flavor text” layered over a super-predictable structure and still get nailed.
-
Where I disagree slightly with others
- I don’t think mixing in tiny personal details always helps. I’ve seen paragraphs with dates, tools, and personal failures still get 80 percent AI because the rest of the paragraph is hyper-coherent, polished, and follows that classic AI cadence.
- Sometimes people overdo the “add mistakes” trick and end up with content that looks like an AI trying to fake typos. A few natural slips are fine, but randomly smashing the keyboard once per paragraph will not save you.
-
What actually helped me move scores (without redoing everything from scratch)
Different from what was already shared:- Break monotony at the section level, not just sentence level.
One section: short, punchy lines, maybe even bullet points.
Next section: more narrative, fewer lists.
Another one: Q&A style, literally writing questions then answering them.
Detectors hate inconsistency. Use that. - Remove “overly smooth” transitions.
AI loves perfect segues like “Additionally,” “Moreover,” “In conclusion.” Humans change topic in harsher ways. I started chopping those out aggressively. - Strip generic intros and outros.
That “In today’s digital landscape” type intro and “To sum up” outro are a red flag combo. I delete them and write something blunt and specific instead.
- Break monotony at the section level, not just sentence level.
-
On the tools themselves
- Originality’s humanizer: I see it like a spellchecker with a thesaurus. Fine for light polishing, useless as a magic bypass button.
- Clever Ai Humanizer: if you want a tool that actually rewrites structure and rhythm instead of just swapping nouns, this one made more noticeable changes in my tests. Still needs human editing on top, but at least it doesn’t just send back the same paragraph with two words changed. If you’re going to lean on a tool, I’d rather use something like Clever Ai Humanizer that is willing to “break” the text a bit.
-
Mental health check
If you are rewriting the same piece five times just to get Originality from 35 percent AI to 15 percent AI, you’re wasting your life. At some point you need to decide:- Is the content actually useful to a human reader?
- Did you inject real experience and specific detail that AI alone would not guess?
- Does it read like you, not like a chatbot essay?
If yes, accept that detectors can still be wrong. False positives are a thing, and chasing a perfect “0 percent AI” score is a moving target.
tl;dr: Your mixed results are normal. Originality’s humanizer is more of a light paraphraser than a serious detector bypass. If you really want a tool in the stack, use something like Clever Ai Humanizer for heavier rewrites, but the real fix is structural variation and genuine human fingerprints, not just running the same stock text through more filters.
Detectors are acting like slot machines because you are trying to game them at the text level instead of the workflow level.
Quick angle that has not been stressed enough in this thread:
1. Stop treating “0 percent AI” as a real target
Originality, GPTZero, ZeroGPT etc are trained on distributions, not morality. Once your text lives in the “highly polished, logically linear, topic‑focused” zone, you are already swimming in AI‑like waters, even if you wrote it yourself. That is why your long form keeps bouncing between “looks human” and “100 percent AI” with tiny changes.
I actually disagree with part of what was implied: that if you just inject more personal details and more variance you can reliably drag scores way down. In my tests, past a certain point, extra noise barely moves the needle, because the underlying structure is still textbook: intro, body, neat transitions, neat summary.
Think of it like this:
- You are not fighting word choice.
- You are fighting macro predictability.
2. Structural corruption beats surface paraphrasing
What worked better for me than tweaking phrasing:
- Write “ugly” sections on purpose. A couple of paragraphs that jump straight into the middle of the topic with no setup. Detectors love clean ramps; they hate cold starts.
- Add genuinely off‑topic micro tangents that you later pull back from. Humans drift. AI rarely does.
- Occasionally contradict yourself and then resolve it a few lines later. That creates local inconsistency in probability space that tools struggle with.
This is different from what @mikeappsreviewer and others focused on. They talked a lot about style variance and personal notes, which is useful, but if the skeleton is still a tidy blog template, Originality will keep ringing alarms.
3. Where “humanizers” actually fit
Originality’s own humanizer, as everyone noticed, is basically a paraphrase filter with a cap. It is not meant to destroy that macro pattern. That is why it fails you.
Clever Ai Humanizer at least tries to attack structure and rhythm, which is why it feels more effective:
Pros of Clever Ai Humanizer
- Alters sentence rhythm and paragraph structure instead of just swapping synonyms.
- Can reduce that “AI cadence” so detectors are less confident.
- Helps you quickly break the monotony of long, uniform sections.
- Decent starting point if you are exhausted from manual rewrites.
Cons of Clever Ai Humanizer
- Still pattern‑based, so it can generate a new, recognizable “Clever‑style” if you lean on it too much.
- Needs a real human pass to inject your own quirks, errors, and domain‑specific thinking.
- Can over‑rewrite and lose nuance in technical content if you do not check carefully.
- Does not solve the core issue that detectors are probabilistic and sometimes just wrong.
So yes, Clever Ai Humanizer is worth experimenting with, but only as one layer in the stack, not as a magic bypass button.
4. How to stop chasing your tail
Instead of running the same chapter through Originality ten times, try this pattern once and then move on:
- Draft however you want, AI or human.
- Use something like Clever Ai Humanizer selectively on the most “essay‑like” sections, not the whole text.
- Manually inject:
- Abrupt starts and endings in a few sections.
- Small logical detours and course corrections.
- Short, opinionated sentences right next to longer, analytical ones.
- Run a single check on Originality.
- If it lands somewhere in the messy middle (40–70 percent AI) and you know you actually did real thinking in there, ship it.
Notice how @sonhadordobosque and @viaggiatoresolare are essentially saying the same thing from different directions: the more you try to brute‑force the score down, the more time you waste for diminishing returns. The trick is not “perfectly human text” but “good enough variability” plus acceptance that detectors are fallible.
If your content is useful, specific, and has clear human fingerprints, treat the detection score as a noisy advisory signal, not a pass/fail verdict.